摘要:
量化投资的七大罪:幸存者偏差、未来数据泄露、样本数据过短、数据窥探data snooping和过拟合overfitting、信号衰减和换手率、异常值、因子多空不对称。
在本文中,讨论了投资者在进行回测和建立量化模型时容易犯的七个常见错误。其中有些可能是所熟悉的,但尽管如此,通过实证也会惊讶于这些偏见的影响。
往期文章:
文章来源于:公z号Logan投资,后台获取相关代码和资料
幸存者偏差
忽视了已退市或者不活跃的股票
幸存者偏差时研究者容易犯的常见错误之一。大多数人都意识到了幸存者偏差,但很少有人理解其意义。
研究者往往只使用那些目前经营的公司来对某些股票投资策略进行回测,这意味着由于破产、退市或者被收购而离开投资领域的股票不被纳入回测范围。
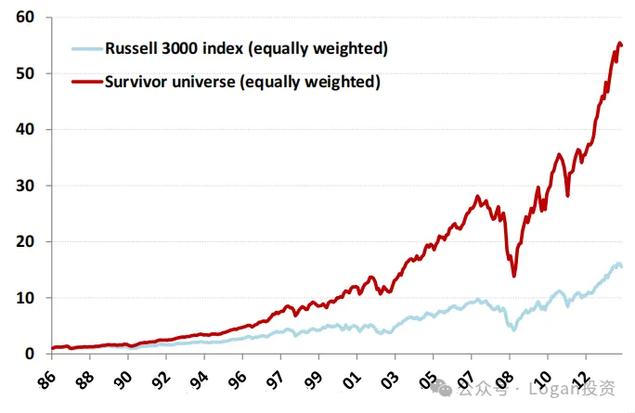
实证:在美国能从86年一直存活至2013年的公司数量和其表现对,如下图
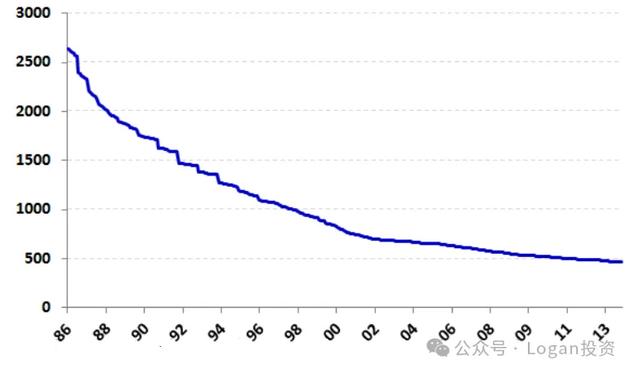
美国:公司数量(蓝色线)/ 存活公司表现对比(红线)
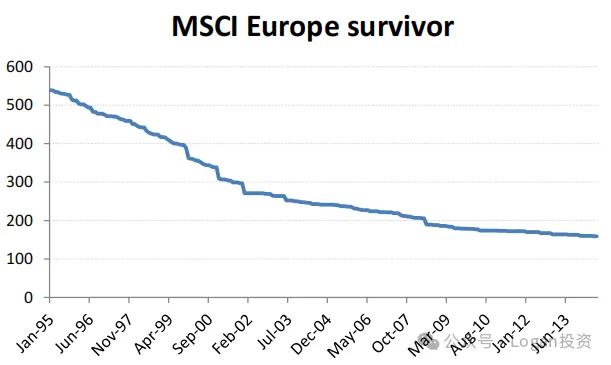
欧洲:公司数量(蓝色线)/ 存活公司表现对比(红线)
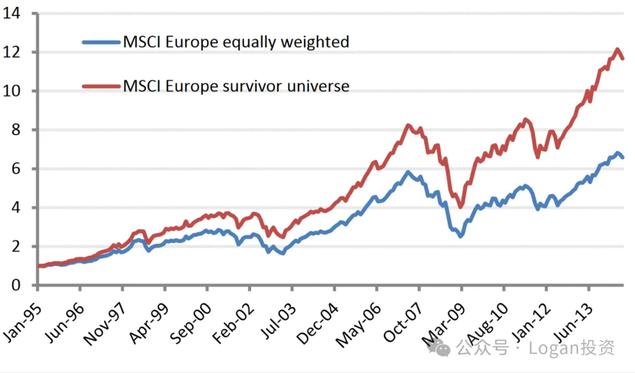
而在进行传统的分组多空的因子分析来判断因子有效性时,就会因为Survivorship bias而产生相反的结论,如上。
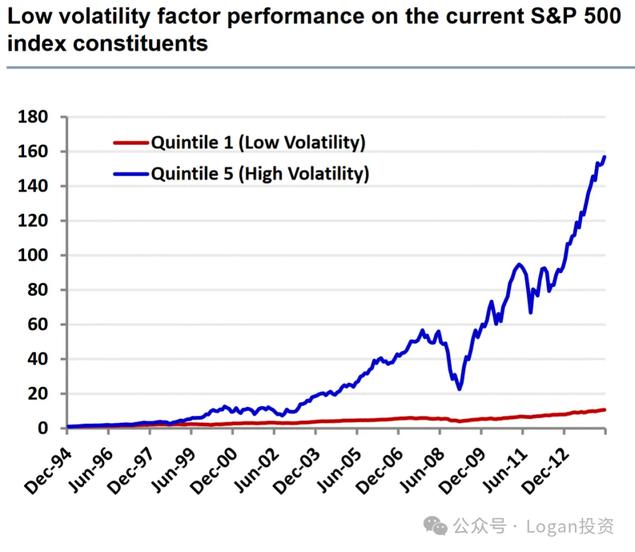
以2012年12月为止最新的标普500成分股进行分析,以波动率因子的大小来进行分组,然后计算每组收益,第一组因子值最小,第五组因子值最大。标普500上的成分股默认都是幸存至今的企业。结果如下图:
而经过调整后的,以历史时间存在的成分股再分组计算收益,结果如下图:
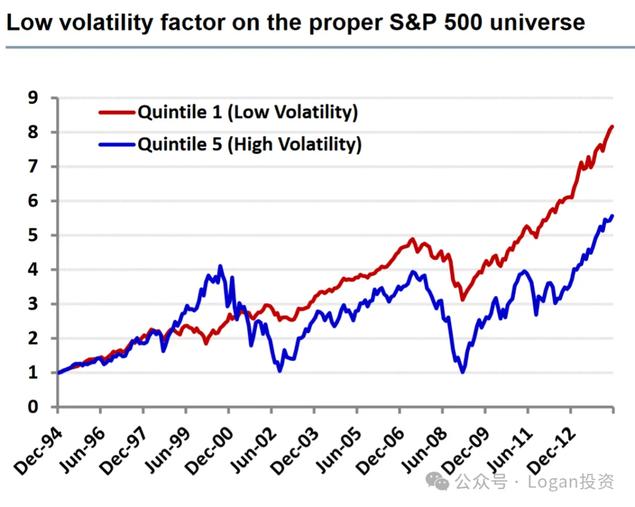
不管是波动率因子越大越好还是越小越好,以上面实证都会发现幸存者偏差会使得在进行因子分析的时候可能会导致出现相反的结论。
涉及未来数据
这一块自然不必多说,不管是涉及到未来函数还是模型学习到了未来的市场模式,都会导致回测高估,这里就说一些。
机器学习训练时未来市场模式的泄露
模型回测时因为训练集和测试集没有进行一定程度的分割而导致模型学习到未来的市场模式的问题我在《科学的机器学习回测方法》中已经讲解到了,在此不多说明。
基本面因子的未来数据泄露
还有对于使用基本面数据进行因子分析和回测的,也会出现较为隐蔽的未来信息泄露问题。例如,A股上市公司的一季报、半年报、三季报和年报的披露截止时间分别在当年的4月底、8月底、10月底和次年4月底公布,一般很少有人在2021年1月就直接调用2020年报的。如果有,那就是提前获取了财务数据。
前复权的问题
前复权行情是保证现在的价格不变,根据分红送股的信息对之前的股票价格进行调整。根据分红送配的信息往过去推时,历史的价格数据包含了现在的信息,也就有了“未来信息”。所以一般因子分析或者回测时用后复权较多一点。
隔夜跳空引发的成交价问题
这一点就是用了t时刻k线的收盘价进行交易,但是实际上已经收盘了,没法交易,回测时却会一直默认能交易进而使用收盘价来成交,本来应该使用第二天的开盘价来作为成交价的,所以这更多会影响日频策略,这一点我在恒指回测上深有感触,恒指很多隔夜跳空的。
数据时间不够长
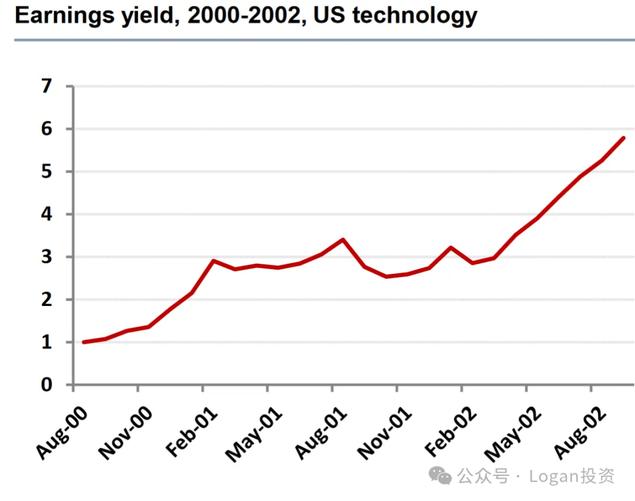
就是样本量太少了。例如以美国每股盈利因子(EPS因子)为例。
第一张图:在1987-1997年间,在罗素3000指数成分股上应用得到的回测曲线,是正收益的。
第二张图:在1997-2000年间,该因子在美国科技股板块的收益曲线是负收益的。
第三张图:在2000-2002年间,该因子在美国科技股板块的收益曲线却又是正收益的。
第四张图:在1995-2013年间,该因子在美国科技股板块上的收益曲线。
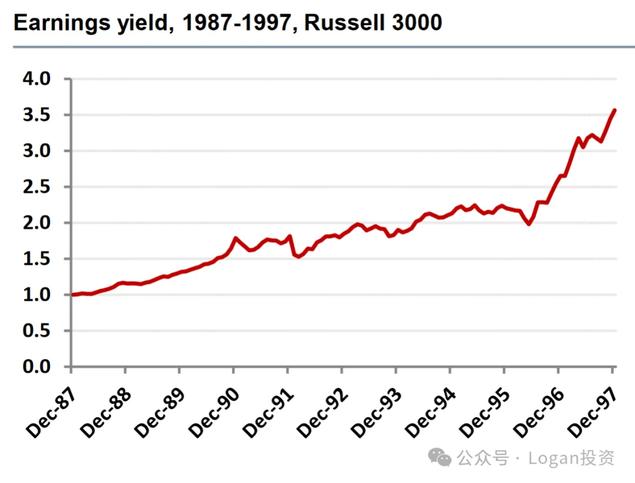
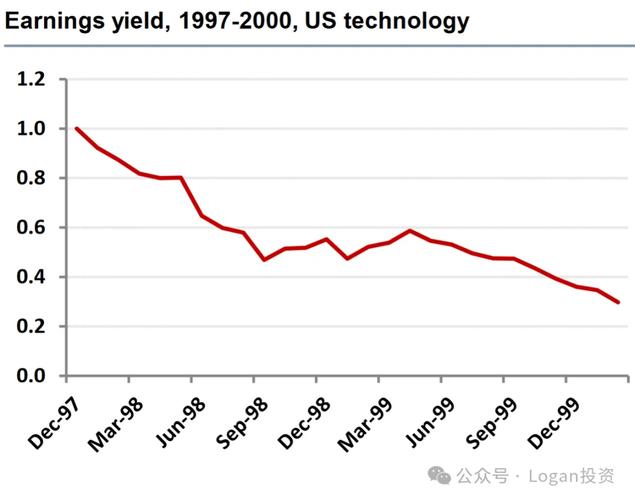
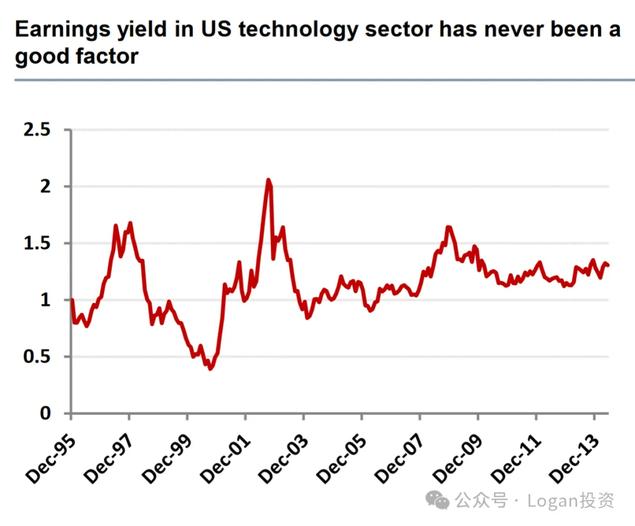
至此也说明了,某些因子在短期或者过去某段较短的时间段内进行回测的时候表现很好,但是当拉长时间再进行回测的时候会发现该因子表现平平。
因为一段时间好不带代表未来长时间有效,所以我们在进行回测的时候除了尽可能的选取较长的时间段,也会在平时不断迭代更新。因为市场是在不断变化的,变化不变。
当然也许也会说有因子能普遍适用于各个品种、股票和市场,那可能就是动量因子咯。
数据窥探和过拟合
RECRUIT
数据窥探data snooping的问题在“因子挖掘界”普遍存在,是指在数据分析过程中,通过尝试多种不同的统计模型和假设检验,直到找到一个“显著”的结果,而不管这个结果是否具有实际意义。这些在计量经济学领域的相关论文中会见得多。比方说就是硬整一个X解释变量和IV工具变量来进行回归分析。
数据窥探的问题在于,它可能会产生误导性的结论,因为“显著”的结果可能是偶然发现的,而不是真正的、可重复的模式。
学者们过度追求因子在原假设下的低 p-value 值(即统计意义上“显著”);不幸的是,由于有意或无意的数据操纵、使用不严谨的统计检验手段、错误地解释 p-value 传达的意义、以及忽视因子本身的业务含义,很多在功利心驱使下被创造出来的收益率因子在实际投资中根本站不住脚。
有兴趣的朋友可以去看川总的《在追逐 p-value 的道路上狂奔,却在科学的道路上渐行渐远》
过拟合-Overfitting
这个遇见得最多,机器学习深度学习过度拟合最后在样本外表现拉跨等。
信号衰减、换手率和交易成本
RECRUIT
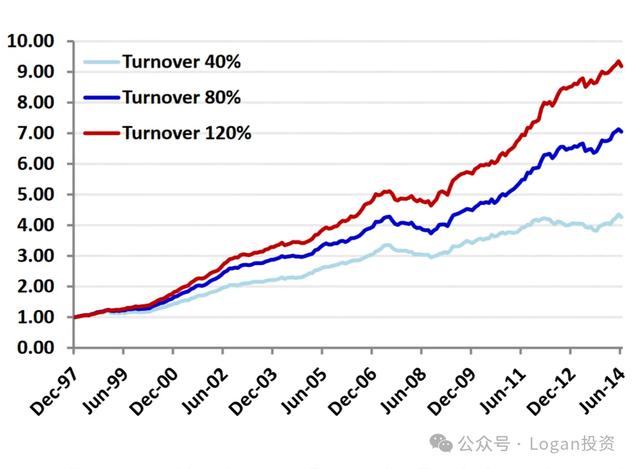
不同的选股因子具有不同的信息衰减特征。更快的衰退信号需要更高的周转率来捕捉其收益。然而,更高的换手率可能会带来更大的交易成本
在投资组合构建过程中加入换手率约束是容易的,但不一定是理想的解决方案,换手率约束可以帮助或损害我们的投资组合绩效。
如下图,在换手率约束下回测收益会因此而减少
不过有一点值得注意的是,策略的低换手率不等于低调仓频率。即你可以约束当前持仓的标的组合中每一只股票在每周交易的次数,但是你也不约束标的组合的调换频率,即不约束究竟什么时候剔除某只股票并调换另一只股票进组合的频次。
正如下图所示,使用低换手率(每年36%的换手率)进行约束后,改变调仓周期仍能提高策略的收益。
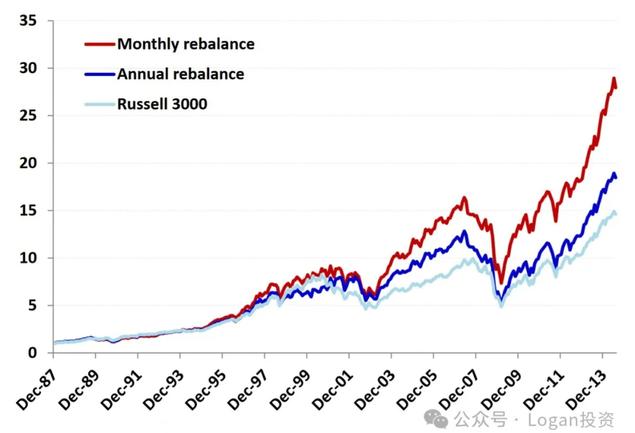
信号衰减
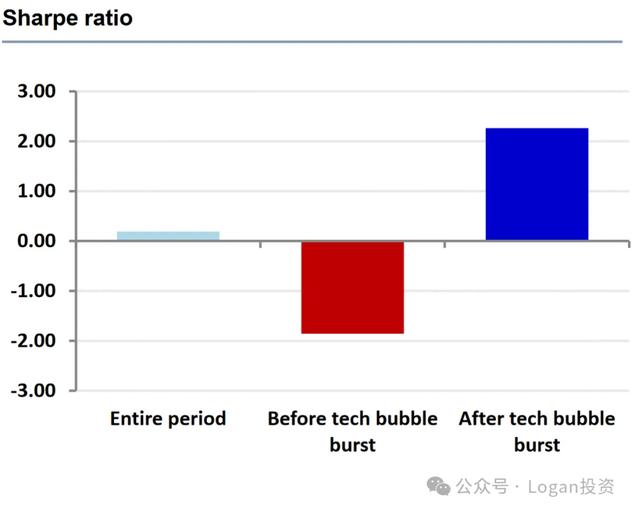
举个例子,一天反转因子——对一天反转因子(也就是说,买入前一天跌幅最大的股票)进行简单的回测,如下图红线,似乎表明短期反转是一个很好的策略。(使用美股的数据进行计算的,不代表中国市场)
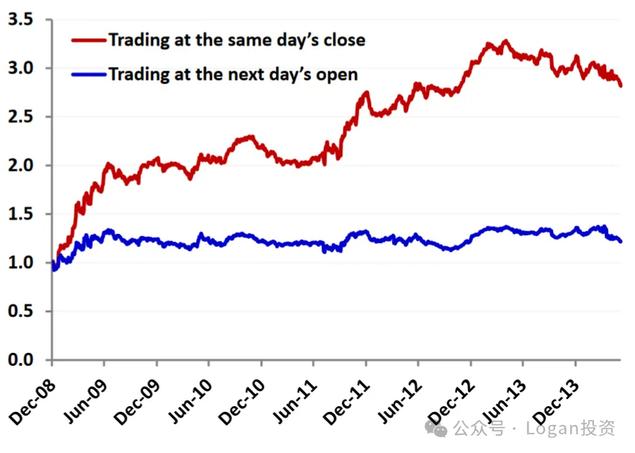
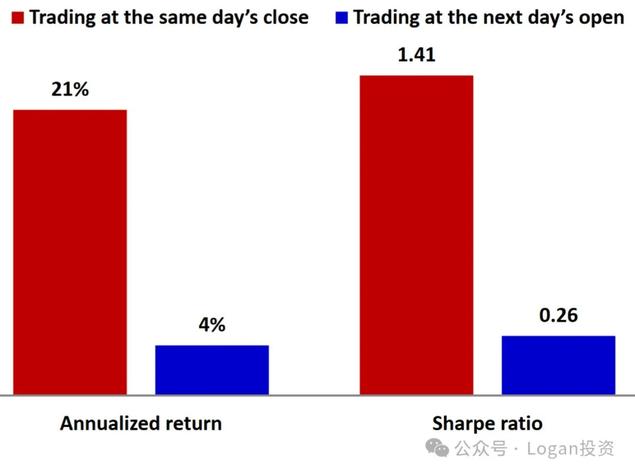
唯一的问题是,该因子本身只能在市场收盘后计算;因此,我们最早能在信号上交易的时间是在第二天开盘时。如果我们能计算出一天的反转因子,并在当天的收盘价上交易,就可以生成一个夏普比率为1.4的一个单因子策略
然而,在现实中,我们只能在第二天开盘交易,而夏普比率骤降至仅为0.3(下降近80 %)
当然,也可以在14:57分的时候运行策略
异常值影响
例如,出现异常值时样本总体均值变化不大,但是此刻标准差却放大了五倍多,因此如果不剔除异常值,大部分股票在该因子上的 zscore 得分将明显偏小,影响该因子在整个 alpha 模型中的贡献。
但也有可能异常值也会包含有效信息,只是在异常值中挖掘信息得出盈利策略的概率较小而已。
处理方法:
①固定比例拉回
分位数Xn%表示序列X的n分位数,则对于此方法,假设以2%为界限,则Xn<2% = max(Xn<2%, X2%) 且 Xn>98% = min(Xn>(100%-2%), X(100%-2%))。
以3倍标准差作为界限拉回也是这种逻辑。
②Z-Score标准化
③Box-Cox 变换
把非正态数据转换为正态数据通常有取对数、开根号、求倒数等方法,这些都可以归为 Box-Cox变换,形式上可以写作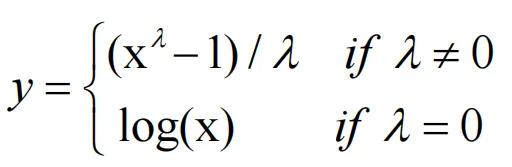
另外,Box-Cox 变换针对的是大于零的正数数据,如果 ,,通常有两种做法,一种是对序列X向上平移μ,使得序列为正,λ和μ可以都做为参数,通过极大似然方法求解。另一种是 Yeo & Johnson (2000)的做法,对大于零和小于零的数采取不同的幂数变化。
④MAD法
MAD 法是针对均值标准差方法的改进,把均值和标准差替换成稳健统计量,样本均值用样本中位数代替,样本标准差用样本MAD(Median Absolute Deviation)代替:
md = median({xi, i=1,2···n})
MAD = median({|xi - md|, i=1,2···n})
MADe = 1.483 * MAD
通常把偏离中位数三倍 MADe(如果样本满足正态分布,且数据量较大,可以证明 )以上的数据作为异常值。和均值标准差方法比,中位数和 MAD 的计算不受极端异常值的影响,结果更加稳健。
⑤排名转换Rank Transformation
将数据集中的每个值替换为其在数据集中的排名。这种方法对于处理异常值特别有效,因为异常值的排名通常不会受到它们原始值大小的影响。
Q:异常值是否能带来额外的有效信息?
A:至少对于动量因子而言是有的
用美股数据进行回测,对于每只股票使用标准化后的动量因子和不标准化后生成的投资组合进行对比
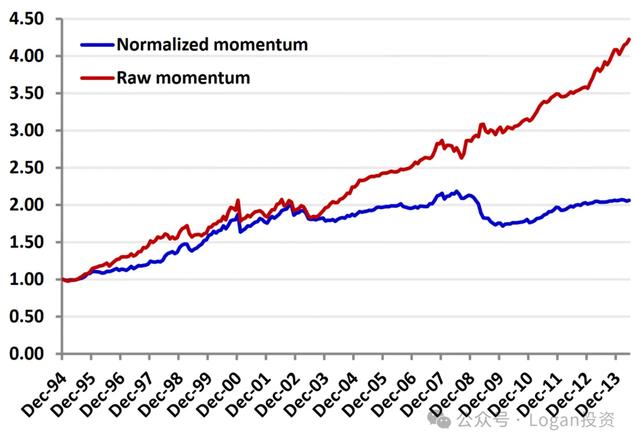
可以看出动量因子不进行标准化的效果会更好,至少是在美股市场而言。
因子的多空模式不对称
采用以下实验,根据因子值等权构建出做多组合和做空组合,然后减去整个所有股票组成的投资组合平均收益率,通过超额收益来判断。
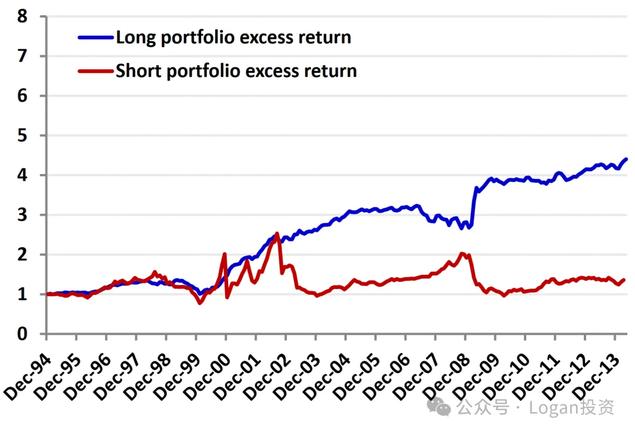
可以看到,多空的超额收益并不对称。
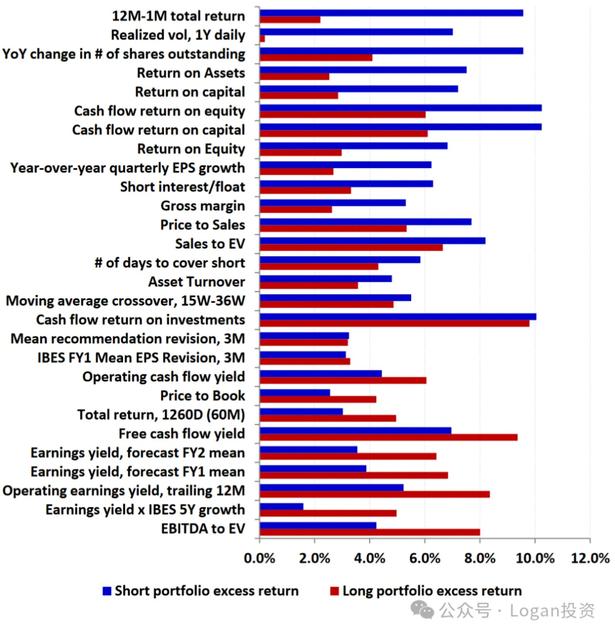
另一方面,考虑下图因子,并根据高频调仓得来的组合超额收益和低频调仓得来的超额收益,两者的差值进行排序,表中越靠上则表示差值越大。可以看到价值因子一般从Long Side获取溢价,而价格动量/反转因子从Short Side产生更多的α。分析师修正因子往往表现出更加对称的收益模式。
其实还有其他一些回测上应该注意的问题
比如对于涉及到使用止盈止损的策略,当某根5分钟k线的最高价和最低价同时触发了止盈止损线,此时是无法判断5分钟内是先在最高价止盈还是最低价止损的,只会会根据代码逻辑的顺序来判断,谁写在前面谁执行。
比如涨跌停板在回测时是否允许买入,是否设置了强制撮合的机制,如下图,设置了涨停板也能交易的机制后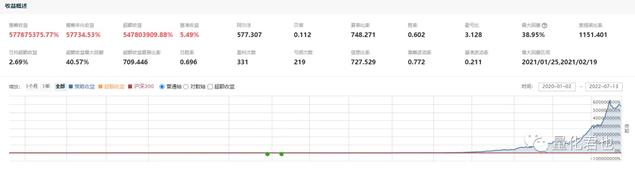
取消后如下图: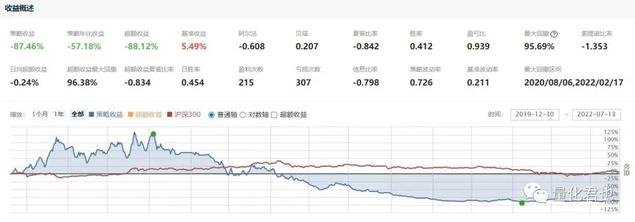
总结
如何避免这七大罪?
1、幸存者偏差:using those companies in the index as of a given point in time。使用特定时间点所能给出的股票池进行回测
2、未来数据泄露:用后复权数据、训练时训练集和测试集不粘连(设置暂停区间)、控制基本面因子的时间
3、样本数据过短:covering multiple economic cycles,使数据覆盖多个经济周期
4、数据窥探和过拟合:交叉验证CV,dropout等避免过拟合
5、信号衰减、换手率和交易成本:限制换手率等措施
6、异常值问题:data transformation,做因子处理,标准化等
7、因子多空不对称:做多的模式和做空的模式进行分离
